SlackにPubMedの新着論文をアラートで流すの便利だよ!と教わったので、早速導入してみました。
GASのランタイムバージョンが上がったり、PubMed本体の仕様が変わりつつあったりするので、そのあたりにも対応できるように改変しています。

目次
元ネタ


変更点・改良点
- 新旧両方のPubMed RSSに対応させた
- GASの新しいランタイム (Chrome V8) に対応させた
- 設定をSpreadsheet上に移し、簡単に編集できるようにした(共同編集もできる!)
- 複数の投稿先(チャネル・個人)を扱えるようにした
- (2021-05-05更新) PubMed RSSが新旧フォーマット統一したのに対応
- (2021-05-05更新) Scopus APIを使ってCiteScore, SNIP, SJRを取得できるようにした
- (2021-05-05更新) mrkdwn向けエスケープ処理を追加
- (2021-09-08更新) Google Apps Scriptのトリガー設定方法が変わっていたので修正
新しいPubMed RSSから得られる情報は従来のものと少し異なります。前の仕様の方が良かったな!
Slack Appの準備
Slackのアカウント取得およびワークスペース等の設定は済ませている前提です。
botが投稿するチャンネルを新しく作る場合は、先に作成しておいてください。
https://api.slack.com/apps にアクセスして、 “Create New App”で新しくアプリを作成してください。ワークスペースはアプリを動かしたいところを選択。名前は適当に。
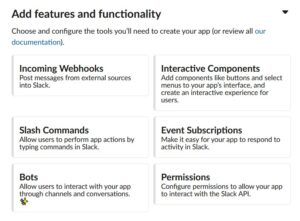
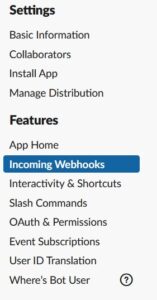
次に、 “Add Features and Functionality”の画面で、”Incoming Webhooks”を押して、有効化します。
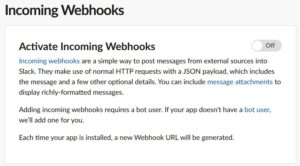
Webhookを有効化したら、画面下部の “Add New Webhook to Workspace”でWebhook URLを生成して下さい。投稿先は、チャンネルまたは個人へのDMが選択できます。URLと投稿先は1対1対応になっているようです。
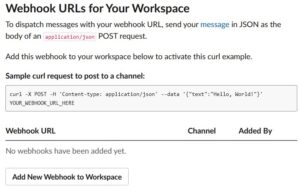
これで完了です。生成したURLはコピー・保存しておいてください。
なお、複数のURLを作成したい場合やURLを再確認したい場合などは、https://api.slack.com/apps で先ほど作成したAppを選択し、左サイドバーから “Incoming Webhooks” を選択すると上記画面を表示することが出来ます。
これでSlack側の準備は完了です。
PubMed RSSの準備
PubMedは新しいUIへの移行期間らしく、新旧混在しています。実はRSSも形式が変わっているので、新しいUIからRSS feedを生成すると元のスクリプトではうまく処理できません。
旧RSS feed: https://eutils.ncbi.nlm.nih.gov/entrez/eutils/~
新RSS feed: https://pubmed.ncbi.nlm.nih.gov/rss/search/~
新RSSはURL内のパラメータでエントリ表示数も変更することができるようになっていますが、旧RSSよりも引用情報が取得しにくくなっています。
今回紹介するスクリプトでは、どちらのRSS feedでも情報を取得できるように改変を加えています。ご自身の使いたい方を選択してください!
(2021-05-05追記) 新旧どちらのURLでも同じ形式のRSSが届くようになりました。(旧URLでも新しい形式のRSSになる)
ここでは、新UIでのRSS Feedの取得方法を紹介します。旧UIでの取得方法は記事上部の元ネタをご参照ください。
まず、PubMedで普通に検索します。Advanced Searchや文献の種類(Reviewなど)の絞り込みもRSS feedの結果に反映されるので、必要な方はここで設定してください。
欲しい条件での検索結果が出たら、”Create RSS”でfeed URLを生成します。
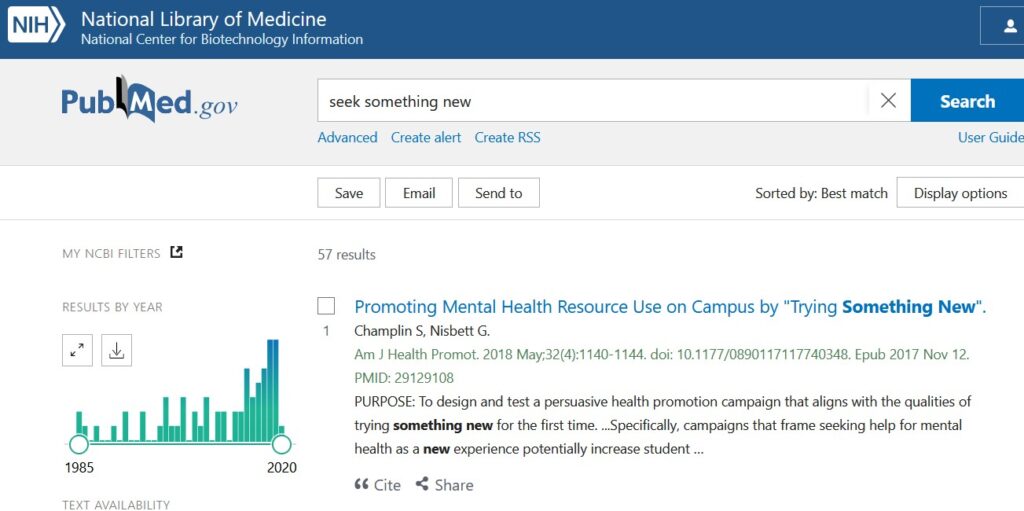
青四角の “Create RSS” を押すと、専用のRSS Feed URLが発行されます。 “COPY”を押してクリップボードにコピーして、保存しておきましょう。
このURLはどこかに保存されることが多分ないので、無くしてしまったら改めて検索し直してRSSを再発行してください。
これで、PubMed RSSのfeed URLが入手できました。あとはGoogle Sheetの設定をするだけです。
Google Spreadsheet + GASの設定
自分のGoogleアカウントで作成してもいいですが、研究室の人に見えても良いメールアドレスにしておいた方が良いと思います。
Google Driveの任意の場所で、「新規 → Google スプレッドシート」で新しくファイルを作成します。ファイル名は任意で構いません。
Spreadsheetの設定
シートを2枚用意します。1枚目のシート名を”RSS”、2枚目のシート名を”webhooks”としてください。
1枚目の”RSS”シートを設定します
1行目のタイトル “Keyword, RSS Feed URL, …” を、下図と同じように入力してください。
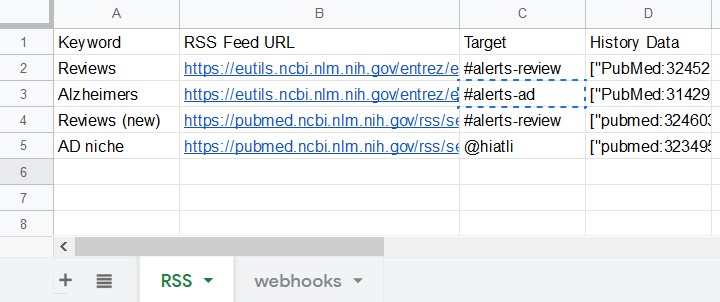
シート1枚目の2行目以降に、自分の設定を入力します。
A列 (Keyword) は、検索RSSのタイトルです。
B列 (RSS Feed URL) は、”PubMed RSSの設定”で取得したfeed URLを入力して下さい。
C列 (Target) は、投稿するチャンネル等を入力してください。次の項で設定する”webhooks”シートに記述されていないチャンネルには投稿できません。
D列 (History Data) は、取得履歴を自動的に保存する場所なので何も入力しないでください。
2枚目の”webhooks”シートを、下図のように設定してください。
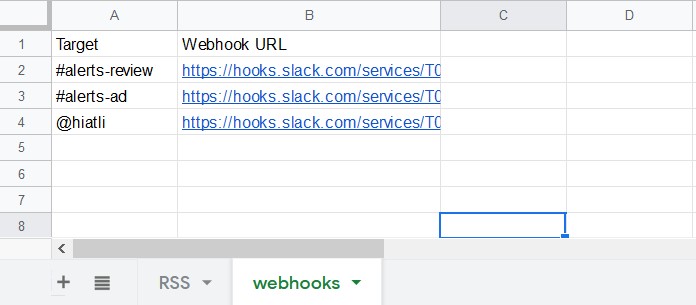
Target列は、”RSS”シートのTargetと同じ文字列である必要があります。
Webhook URLは、 “Slack Appの準備” で生成したURLを入力してください。
GASの設定
先ほど設定したGoogle スプレッドシートの「拡張機能 → Apps Script」でスクリプトエディタを開いてください。
元々入力されている function myFunction() {} は全て削除し、以下のコードをコピペします。尚、コードの安全性は万全ではないので、内容をよく確認し、自らの責任において実行してください。
(2021-05-05) コード内容を更新しました。更新内容はページ最上部参照。Scopusデータベースの使い方はデフォルトで無効にしています。コードを読んで分かる場合に使ってみてください。
function PubMedSlack() {
// 基本設定
var rss_sheet_name = "RSS";
var webhook_sheet_name = "webhooks";
var notify_text = "Here are {ITEM_NUMBER} new papers for *{KEYWORD}* :eyes:";
var N_IN_BLOCK = 5;
var rw_length = "{ITEM_NUMBER}"; //アイテムの数
var rw_keyword = "{KEYWORD}"; //キーワード(RSSリストのkeywordに対応)
var ns_dc = XmlService.getNamespace("http://purl.org/dc/elements/1.1/");
var pm_rss_legacy = "https://eutils.ncbi.nlm.nih.gov/entrez/eutils/";
var pm_rss_new = "https://pubmed.ncbi.nlm.nih.gov/rss/search/";
//Scopusを使ってCiteScoreなどを表示させる時に設定する。PubMedとScopus両方のAPI Keyが必要。
var enable_scopus_database = 0;
var display_pmid = 0;
var display_citescore = 0;
var display_snip = 0;
var display_sjr = 0;
var pubmed_api_key = '';
var scopus_api_key = '';
var pm_base_url = 'https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esummary.fcgi?db=pubmed&version=2.0&id={ID}&api_key='+pubmed_api_key;
var pm_reptxt = '{ID}';
var pm_params = {
"method": "get",
"muteHttpExceptions": false,
"headers": {
"accept": "text/xml",
"timeout": "20000"
}
};
var sc_base_url = 'https://api.elsevier.com/content/serial/title/issn/{ISSN}?apiKey='+scopus_api_key;
var sc_reptxt = '{ISSN}';
var sc_params = {
"method": "get",
"muteHttpExceptions": false,
"headers": {
"accept": "text/xml",
"timeout": "20000"
}
};
var mrkdwnEscape = function (string) {
if(typeof string !== 'string') {
return string;
}
return string.replace(/[&<>]/g, function(match) {
return {
'&': '&',
'<': '<',
'>': '>',
}[match]
});
}
// スプレッドシートからRSSとWebhookのURLを取得
var ss = SpreadsheetApp.getActiveSpreadsheet();
// rss_list[row:1-max][col:1-4] = "value"
// col=1: keyword
// col=2: RSS URL
// col=3: Target ID
// col=4: History Data
var rss_sheet = ss.getSheetByName(rss_sheet_name);
var rss_total_num = rss_sheet.getLastRow() - 1;
var rss_list = rss_sheet.getRange(2, 1, rss_total_num+1, 4).getValues();
// webhook_list["target_id"] = "Webhook URL" となるように格納する
var webhook_sheet = ss.getSheetByName(webhook_sheet_name);
var webhook_total_num = webhook_sheet.getLastRow() - 1;
var webhook_table = webhook_sheet.getRange(2, 1, webhook_total_num+1, 2).getValues();
var webhook_list = {};
for (var i=0; i<webhook_total_num; i++) {
webhook_list[webhook_table[i][0].toString().trim()] = webhook_table[i][1].toString().trim();
}
for (var i=0; i<rss_total_num; i++) {
var keyword = rss_list[i][0].toString().trim();
var rss_url = rss_list[i][1].toString().trim();
var target = rss_list[i][2].toString().trim();
try {
var history = JSON.parse(rss_list[i][3]);
} catch (e) {
var history = [''];
}
var webhook_url = webhook_list[target];
if (!webhook_url) {
Logger.log("webhook url not found: "+target);
continue;
}
// Fetch
try {
var rss_text = UrlFetchApp.fetch(rss_url).getContentText(); // たまにPubMedが404エラーを出すことがあるのでtryで回避
} catch (e) {
continue; // もしエラーが出てもとりあえず無視(次回fetchできれば良しとする)
}
// Parse
// 新しい順に並んでいるので逆転させる
var rss = XmlService.parse(rss_text);
var items = rss.getRootElement().getChildren('channel')[0].getChildren('item').reverse();
// Check new items
var news = [];
for (var item of items) {
if (history.indexOf(item.getChild('guid').getText()) < 0) {
news.push(item);
}
}
if (news.length > 0) {
// Prepare blocks
var blocks = [{
type: "section",
text: {
type:"mrkdwn",
text:notify_text.replace(rw_length, news.length).replace(rw_keyword, keyword)
}
}];
var txt = '';
var j = 1;
for (var item of news) {
// rss_urlの形式によってデータの抽出方法を変えていたが、書式が統一されたためルーチンも統一した。 (2021-02-27)
if (rss_url.indexOf(pm_rss_legacy) === 0 |rss_url.indexOf(pm_rss_new) === 0) {
var link = item.getChild('link').getText();
var title = item.getChild('title', ns_dc).getText();
var title_escaped = mrkdwnEscape(title);
var title_ja = LanguageApp.translate(title,'en','ja');
var authors = item.getChildren('creator', ns_dc);
if (authors.length > 0) {
var author = authors[0].getText();
if (authors.length>1) {
author += ", _et al._";
}
} else {
var author = "No Author";
}
var journal = item.getChild('source', ns_dc).getText();
var date = item.getChild('date', ns_dc).getText();
var pmid = item.getChild('guid').getText().substr(7);
var journal_issn = '';
var sjr = '?';
var snip = '?';
var citescore = '?';
if (enable_scopus_database) {
try {
var pm_xmlText = UrlFetchApp.fetch(pm_base_url.replace(pm_reptxt,pmid), pm_params).getContentText();
var pm_xml = XmlService.parse(pm_xmlText).getRootElement().getChild('DocumentSummarySet');
if (pm_xml.getAttribute('status').getValue() == 'OK') {
var article = pm_xml.getChild('DocumentSummary');
try {
journal_issn = article.getChild('ISSN').getText();
} catch (e) {
journal_issn = '';
}
if (journal_issn == '') {
journal_issn = article.getChild('ESSN').getText();
}
if (journal_issn != '') {
var sc_xmlText = UrlFetchApp.fetch(sc_base_url.replace(sc_reptxt,journal_issn), sc_params).getContentText();
var sc_xml = XmlService.parse(sc_xmlText).getRootElement();
var sc_journal = sc_xml.getChild('entry');
try {
journal = sc_journal.getChild('title', ns_dc).getText();
} catch (e) { }
try {
sjr = sc_journal.getChild('SJRList').getChild('SJR').getText();
} catch (e) {
sjr = '?';
}
try {
snip = sc_journal.getChild('SNIPList').getChild('SNIP').getText();
} catch (e) {
snip = '?';
}
try {
citescore = sc_journal.getChild('citeScoreYearInfoList').getChild('citeScoreCurrentMetric').getText();
} catch (e) {
citescore = '?';
}
}
}
} catch (e) {
journal_issn = '';
}
}
} else {
Logger.log("RSS URL pattern did not match.: "+rss_url);
continue;
};
var additional_data = [];
if (display_pmid) { additional_data.push('PMID=' + pmid); }
if (display_snip) { additional_data.push('SNIP=' + snip); }
if (display_citescore) { additional_data.push('CiteScore=' + citescore); }
if (display_sjr) { additional_data.push('SJR='+ sjr); }
txt += '>*<'+link+'|'+title_escaped+'>*\n>'+title_ja+'\n>'+ author + ' ' + '_*' + journal + '*_ [' + additional_data.join(',') + '] ' + date + '\n \n';
//5記事ごとに1block生成する
//1記事ごとにブロックを生成するとブロック数の上限50にひっかかることがある
//maximum length for the 'text' in a block is 3,000 characters.
//messageあたりは100,000characters
//1記事1メッセージしないのは無料版slackでメッセージ数を節約するため
if ((j%N_IN_BLOCK)==0){
var l = txt.length;
blocks.push({
type: "section",
text: {
type:"mrkdwn",
text: txt
}
});
txt = '';
};
j += 1;
};
if ((j%N_IN_BLOCK)!=1){
blocks.push({
type: "section",
text: {
type:"mrkdwn",
text: txt
}
});
};
var payload = {
text: notify_text.replace(rw_length, news.length).replace(rw_keyword, keyword), //failback sentence
blocks: blocks
};
// Post Slack on Incoming Hook
var options = {
method: "post",
headers: {"Content-type": "application/json"},
payload: JSON.stringify(payload)
};
UrlFetchApp.fetch(webhook_url, options);
// Record fetched items
var new_history = [];
for (var item of items) {
new_history.push(item.getChild('guid').getText());
};
rss_list[i][3] = JSON.stringify(new_history);
};
};
//historyデータ書き込み
var history_column = rss_sheet.getRange(2, 4, rss_total_num+1, 4);
for (i=0; i<rss_total_num; i++) {
history_column.getCell(i+1, 1).setValue(rss_list[i][3]);
};
};うまくいっていれば、実行ボタン ▶ を押して権限承認を経るとSlackの該当チャンネルに投稿されるはずです。
スクリプトの定期実行
ここまでくればあともう一息です。
画面左端のペインから「トリガー」を選択します。
画面右下の青い「トリガーを追加」を押して設定します。以下は一例なので、好きなように設定を変更しても大丈夫です。
- 実行する関数を選択: PubMedSlack
- 実行するデプロイを選択: Head
- イベントのソースを選択: 時間主導型
- 時間ベースのトリガーのタイプを選択: 日付ベースのタイマー
- 時刻を選択: 午前 8時~9時
設定が終わったら、ウィンドウ右下の青い「保存」を押してください。
これで設定は全て完了です! お疲れ様でした。
謝辞
元ネタのお二方には多大な感謝を申し上げます。とても助かってますありがとうございます。
大変有益なツールの紹介ありがとうございます。
スクリプトエディタの62行目に関して、
「for-loop 初期化子の後に ; がありません。(行 62、ファイル「コード」)」
というエラーが出るのですが、もし原因がわかりましたら大変ありがたいです。
こんにちは!
表示されているエラーは構文が対応していない時などに出てくるみたいです。GASのランタイムがRhinoになっていませんか?
上記スクリプトはV8ランタイムで動作確認したので、プロジェクトの設定で「V8ランタイムを有効にする」にチェックが入っているかどうか確認してみてください。
または、for-in構文に置き換えてみるのも手です。以下の修正を試してみてください。
– for (var item of items) {
+ for (var item_idx in items) {
+ var item = items[item_idx];
お役に立てば幸いです。
記事作成から1年間でPubMedのRSS仕様がちょくちょく変わったりしていたので、対応したバージョンで記事内容を更新しました。
大変有用なツールについて公開頂き誠にありがとうございます。
長らく、愛用させていただいていたのですが、年明けよりエラーが発生しております。
改修が手元ではできませんでした。もし仕様変更など、ご存じのことがあれば伺えれば幸いです。
Exception: Request failed for https://hooks.slack.com returned code 400. Truncated server response: invalid_blocks (use muteHttpExceptions option to examine full response)
PubMedSlack @ コード.gs:246
ご多用のことと存じますが、何卒よろしくお願い申し上げます。
someさん、こんにちは!
手元でスクリプトを現行ver.で実行してみましたが、同様のエラーが確認できませんでした。
Slackからinvalid_blocksのエラーが返されているので、投稿したメッセージの内容に何らかの問題があるのだと思います。
エラーが出ている行の直前に
Logger.log(JSON.stringify(payload))を挿入して、ログに出力されたテキストをコピーしてSlackのBlock Kit Builderにペーストしてみて下さい。(ペーストしたあと、2行目の「”text”: ~」の行を削除する必要があります)
もし正しく認識されない場合は、赤い波線が引かれると思うので、ポップアップメッセージからエラー内容を特定して下さい。
ご回答、ご検証誠にありがとうございます。
ご指示いただきました方法で確認したところ、以下の回答を得ました。
@invalid additional property: text
@failed to match all allowed schemas
@must be less than 3001 characters
これまでの検索では最大100件をRSSしていたのですが、途中で文字数の多い文献が含まれたのかもしれません。結果、RSS側の件数を制限し、urlの再発行から実行し直したことで無事に解決しました。
心より御礼申し上げます!本当にありがとうございました。
良かったですー!